Computational AI Development and Explanation







In the present day we currently reside in where information is so readily available, we have stumbled upon a point in time where your typical person has a wealth of knowledge at their fingertips. The Information Age is often characterised by one’s ability to access this overwhelming amount of data, and with this accessibility comes the inherent desire to create a better understanding of the evolving technology surrounding us.
The Information Age began in the 1970s and is also referred to as the Computer Age, Digital Age, or New Media Age. This historical moment represents a critical point in our species evolution because it signifies the rapid shift from traditional industry that was established by the Industrial Revolution to an economy primarily based on information technology.
We are currently still within the Information Age, and in this current phase information and data is more accessible than it’s ever been before. Here are a few statistics that will aid in creating an understanding of how fast information technology is advancing and expanding:
· There are 4.88 billion internet users in the world.
· There are 5.29 billion mobile phone users in the world.
· It’s predicted that there will be 38.6 billion IoT devices around the world by 2025.
· There are 1.35 million tech start-ups in the world.
· 90% of the world’s data was collected in the last two years.
· There are over 600,000 new internet users each day, on average.
Like many others, due to this natural desire for information, you most definitely have come across the current buzzwords existing within the world of technology, such as Artificial Intelligence (AI) and Machine Learning (ML). And because these words are thrown around and can be found in almost every instance of emerging technology, it begs the question of a deeper and greater understanding.
In this article, instead of focusing on the generic buzzwords which are often associated with AI, we will take an in depth look at the intricacies surrounding computational AI and what allows it to function the way it does.
Over the past few years, a significant amount of hype and excitement has begun to engulf the term ‘AI’ as leaders within the tech industry have been scrambling to promote how their new services and products utilise AI. To give some perspective on how vast the expansion of AI is, in 2021, the global expenditure on AI investment reached £59.5 billion ($77.5 billion), which also represents a significant increase from the previous record set the year before which was £27.6 billion($36 billion). The issue with this is that these gigantic tech conglomerates have created a lot of misunderstanding on the topic and in most cases only incorporate one small component of AI, without providing any real description into the innerworkings of the technology.
How does AI work?
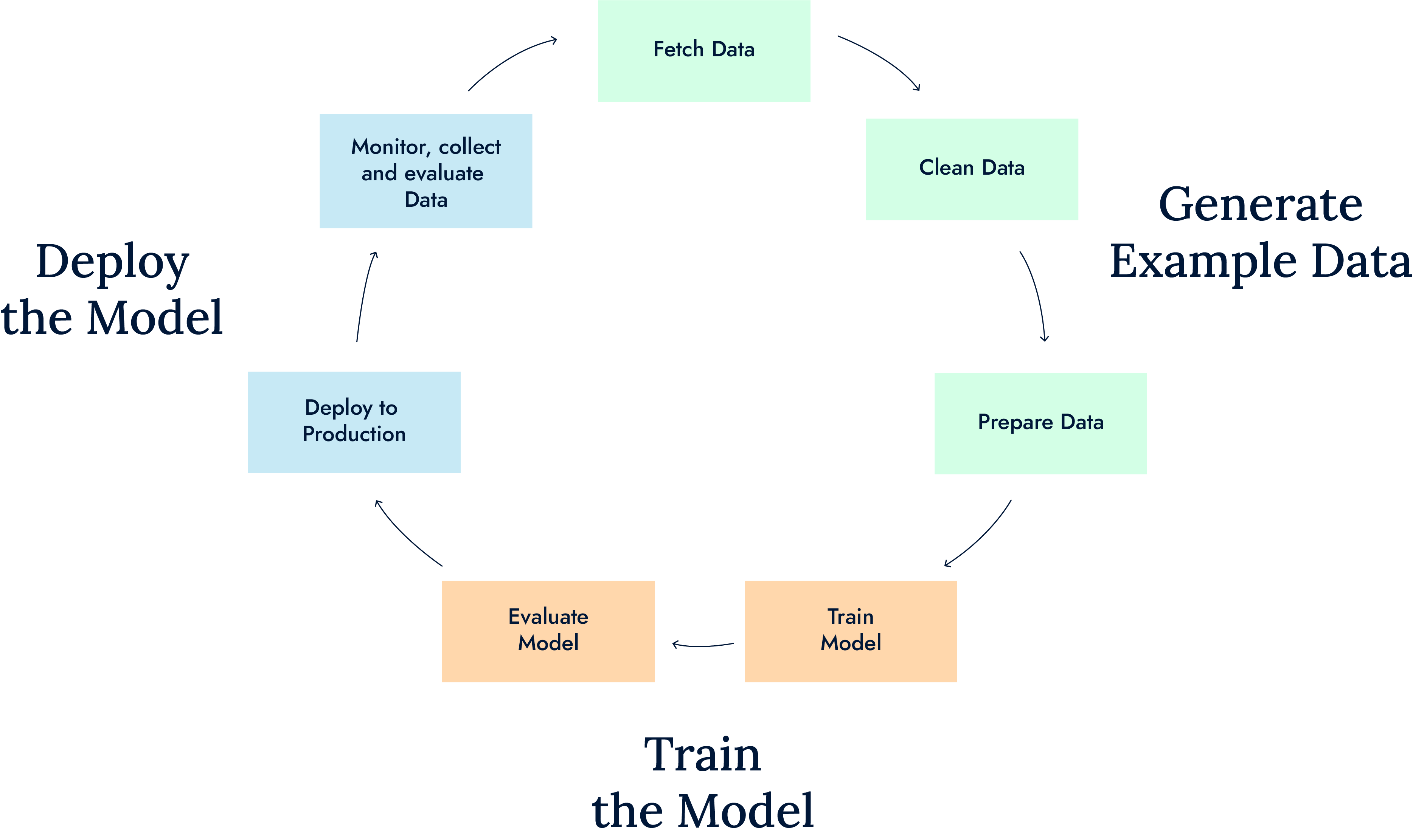
Typical AI systems function by ingesting significant amounts of categorized and labelled training data, this training data is then analysed for any patterns and correlations between data points that may occur within the training set, these previously identified patterns can then be used to perform predictions on possible future states.
Writing and training algorithms to perform these predictions can be a daunting task, and there is an entire pipeline of procedures that need to be followed to achieve an algorithm that outputs accurate predictions.
There are three primary cognitive skills which are of utmost importance when AI programming, thus being: learning, reasoning, and self-correction.
The learning process which encapsulates these cognitive skills takes the aforementioned large amounts of labelled training data and runs it through a set of rules with the intention of transforming it into actionable information. The set of rules can also be referred to as the algorithm itself and is entirely responsible for providing the computational logic which translates into a step-by-step set of instructions on how to perform and complete specific tasks.
The reasoning process is the aspect of AI programming in which you decide the appropriate type of algorithm to solve a specific problem. This brings us to the branch of AI known as Machine Learning.
Machine Learning is the computational side of AI which allows specific goals to be realised. In short, ML is a method of data analysis that automates analytical model building and incorporates the idea that systems can learn from data, identify patterns and correlations between data points, and finally, make decisions with minimal or no human interaction at all, as we previously discussed.
Choosing the right algorithm to achieve a desired outcome, will require a basic understanding of neural networks, as this is the foundation of the computational process behind Machine Learning, and will provide the framework which recognises the underlying relationships within the datasets that are fed into the algorithm.
The self-correction process is the aspect of AI programming, which is closely associated with fine-tuning and optimisation, with the intention of achieving the most accurate result possible. Over many iterations of training, new information comes to light regarding ways in which certain aspects of the development pipeline are inefficient, or simply could be improved. These improvements are typically made with the intention of achieving a higher overall accuracy.
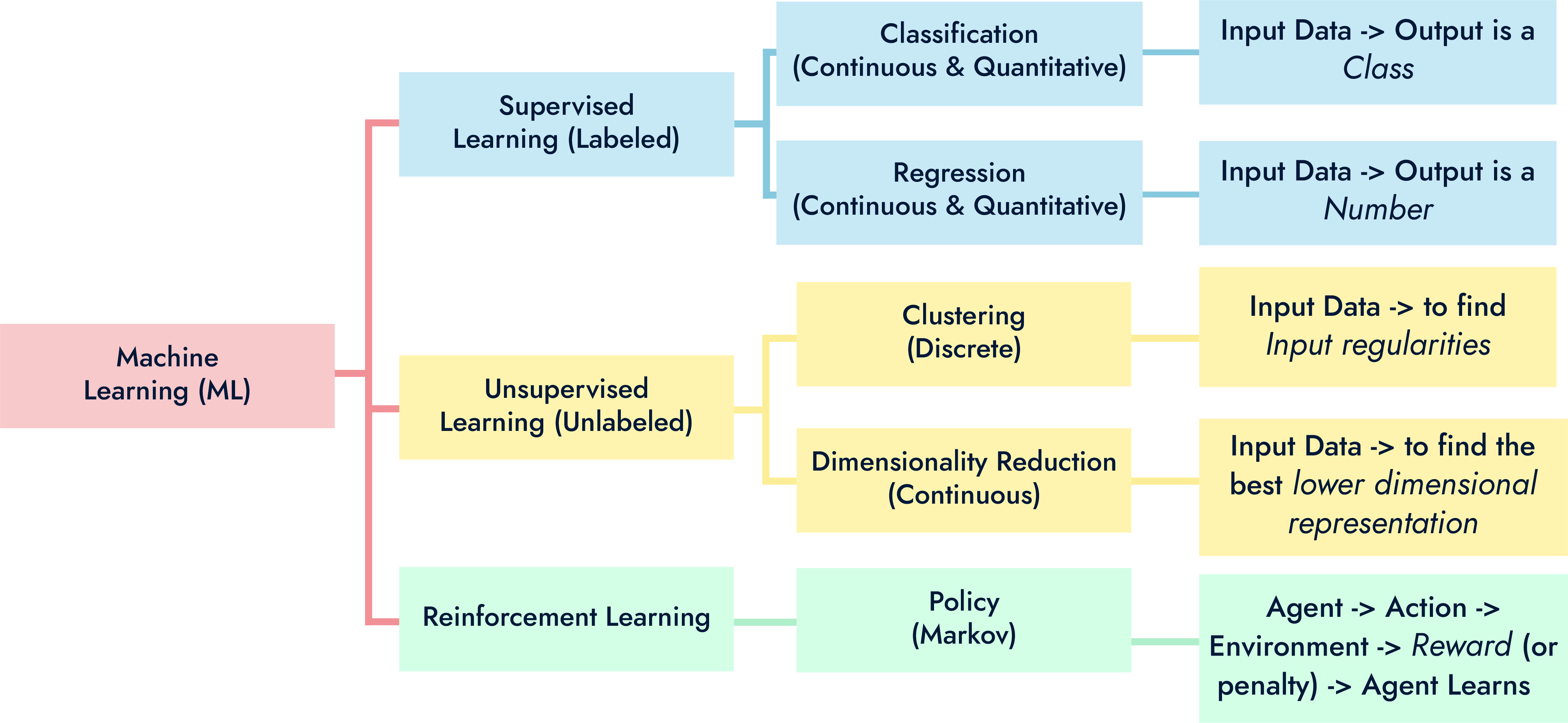
What are Neural Networks?
“Neural networks, also known as artificial neural networks (ANNs) or simulated neural networks (SNNs), are a subset of machine learning and are at the heart of deep learning algorithms. Their name and structure are inspired by the human brain, mimicking the way that biological neurons signal to one another.” - (IBM, 2020)
There are several unique layers which encompass a neural network, defining what it is and the way in which it functions. A collection of connected nodes called artificial neurons are what neural networks are based on. These nodes consist of several layers being an input layer, several hidden layers, and an output layer. There are connections which are formed between each node, and each node has its own weight which is the parameter within a neural network that transforms input data within the network’s hidden layers.
Regarding the use cases of neural networks, the most ideal scenario is on the subject of classification issues. NN’s possess the capability to adapt according to the various types of data which are inputted, thus making them adaptive. They also retain an incredible level of flexibility concerning its applicability to real-world scenarios, particularly when it comes to modelling complex solutions to do with prediction, image recognition, or natural language processing.
Real World Example:
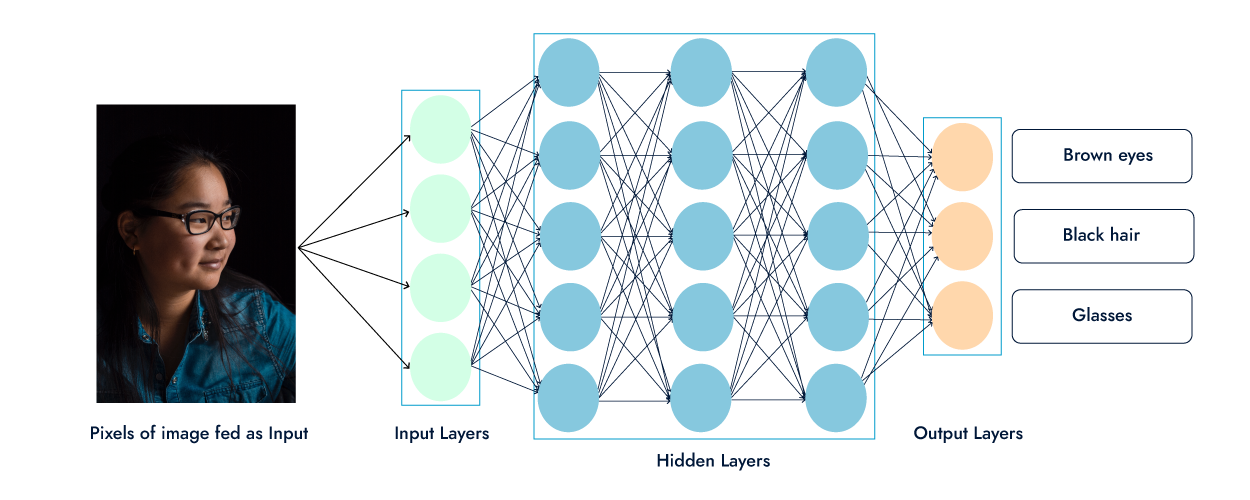
Let’s say we want to create a facial recognition algorithm, there are a few key components which will encapsulate this process, thus being: the data frame, the transformer, the estimator, and the evaluator.
To begin with we would need to choose an appropriate algorithm, when dealing with images a Convolutional Neural Network (CNN) would be appropriate, as it specialises in image inputs. We would then need a dataset comprising of images of peoples faces, seeing as this is a novel implementation, 1000 images should be enough for a proof of concept.
Our 1000 images of people’s faces comprise our data frame, we now need to clean the dataset by getting rid of any images which aren’t appropriate for the algorithm, and label/categorize the dataset. What this means is that we would manually need to sort through every single image within the dataset and categorise it with specific labels. For example, if we have an image of a Caucasian female with brown eyes, black hair, and glasses, we will need to label the image with all of these attributes, and then proceed to repeat this step for the entire dataset.
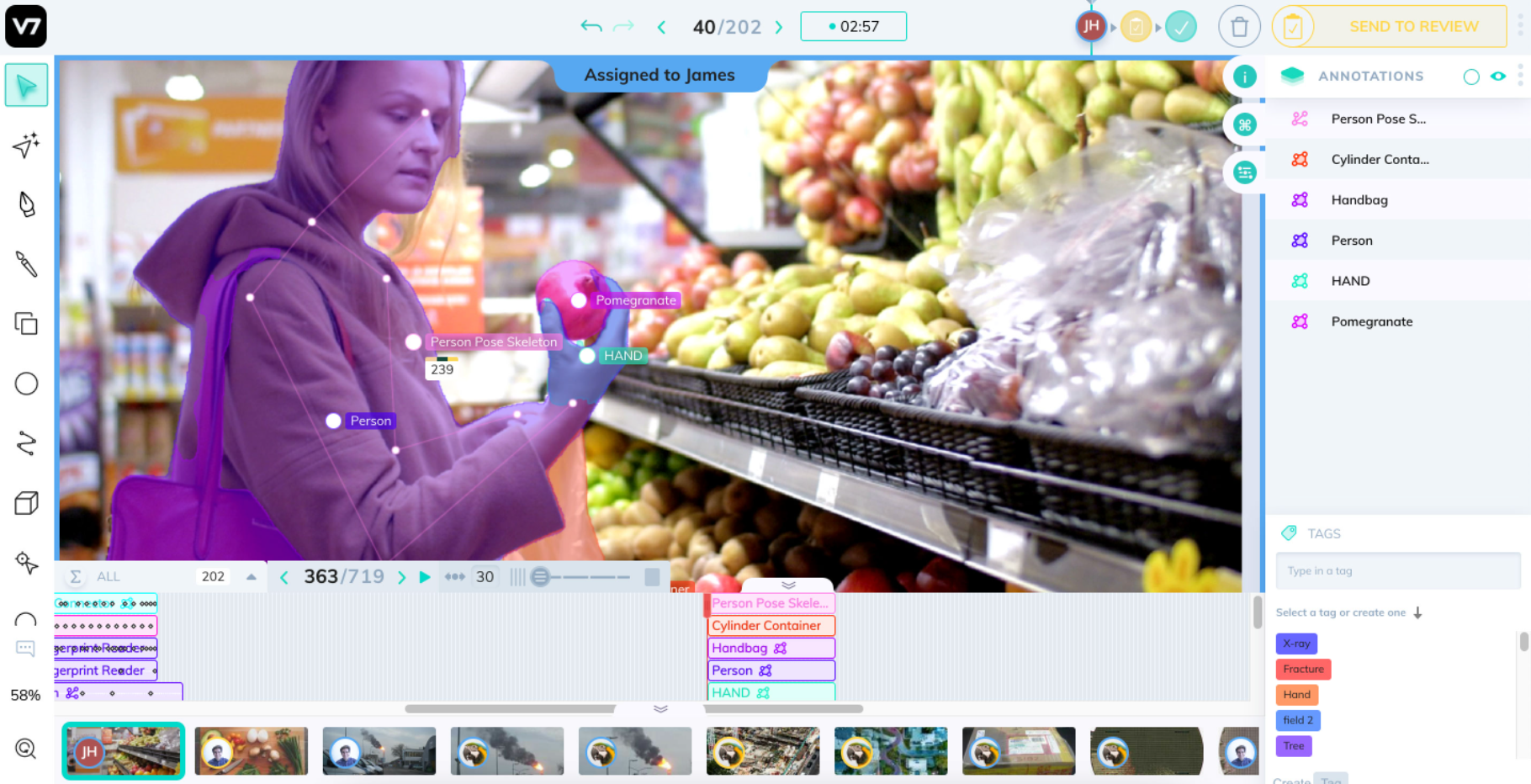
Once annotation of the dataset is complete, it is time to perform pre-processing before input into the algorithm. Pre-processing refers to the transformations applied to data before feeding it into the algorithm. One of the reasons for doing this is to ensure higher accuracy in regard to the training results. An example of pre-processing would be image augmentation, in which we can augment all of the images within the dataset based on specific parameters, such as orientation, blur, brightness, pan, zoom, etc. By doing this we can artificially expand the size of the dataset because a single image could potentially be augmented into 10 images which all look slightly different, therefore providing the algorithm with more training data, and more training data typically results in a more accurate prediction.
The data is now prepared to be fed into the algorithm, and so the next step of the process is to define the model constructs. Before doing this, we will split our dataset into a test and train split. What this means is that we will set aside 40% of our images from the dataset for the purpose of validating the accuracy of the algorithm, and we will use the other 60% of our images to physically train the algorithm.
Upon defining model constructs, we define the specific parameters that serve as our instructions for processing, interpreting, and analysing the images to serve our purpose. Most importantly, the model would need to compromise of several major branches which represent the number of attributes we are aiming to identify within each image(skin colour, hair colour, eye colour, etc).
Once the model parameters are defined it is time for training. The labelled dataset is fed into the algorithm, where specific calculations are performed based on the criteria that was defined. A method known as batch processing is typically used to feed images into the algorithm in batches as to not overwhelm the training process, and several iterations of training are completed until the algorithm can successfully identify the attributes that exist within each image with no human intervention. This is known as supervised training, and by achieving an accurate result, it would be possible to apply this same algorithm to a totally new and unseen dataset and the algorithm would be able to perform facial attribute recognition.
The final step of the pipeline is evaluation, this involves using the 40% of our dataset that we previously labelled and set aside to now evaluate the result of the training, by applying the algorithms output predictions against the set of validation data. This process will lead us to determine a final validation accuracy of the training data.
Final thoughts:
The above use case was included in this article for demonstrating the applicability of AI in a real-world scenario, but to better understand why it’s so important to us as a developing society, let’s discuss a few key factors on the topic of AI.
One of the many reasons why Machine Learning in particular is so important is due to the increasingly enormous volumes and variety of data that currently exist, developing a way to concisely process and handle this data is an overbearing task, which becomes manageable with the help of AI, such as in this use case scenario where we classified people’s faces based on their appearance. A system like this could be immensely helpful for law enforcement agencies to help identify people, or even for tech companies that produce smartphones, as it’s a standard feature in modern phones to offer facial recognition capabilities when it comes to unlocking the device.
The intention of this article was to bring awareness to the intricacies surrounding AI, as well as specifying the importance of the technology and how it’s currently used in almost every industry and subsector of tech. It’s vital for we as a people to understand how the technology surrounding us functions, as there is power in understanding.
Links and Further Reading:
Burns, E., 2022. What is Artificial Intelligence (AI)? Definition, Benefits and Use Cases. [online]SearchEnterpriseAI. Available at: https://www.techtarget.com/searchenterpriseai/definition/AI-Artificial-Intelligence
Accenture, 2022. What Is Artificial Intelligence | Accenture. [online] Accenture.com. Available at: https://www.accenture.com/gb-en/insights/artificial-intelligence-summary-index
Davenport, T., 2022. Machine Learning: What it is and why it matters. [online] Sas.com. Available at: https://www.sas.com/en_in/insights/analytics/machine-learning.html
GeeksforGeeks, 2021. ML | Data Preprocessing in Python - GeeksforGeeks. [online] GeeksforGeeks. Available at: https://www.geeksforgeeks.org/data-preprocessing-machine-learning-python/
Roses-Agoro, J.,2021. Multi_Output_CNN-Facial_Recognition_Algorithm/AppML_report-000992718.pdfat main · jjrosesagoro/Multi_Output_CNN-Facial_Recognition_Algorithm. [online]GitHub. Available at: https://github.com/jjrosesagoro/Multi_Output_CNN-Facial_Recognition_Algorithm/blob/main/AppML_report-000992718.pdf
IBM.com. 2020. What are Neural Networks? [online]Available at: https://www.ibm.com/cloud/learn/neural-networks
McCain, A., 2022. How Fast Is TechnologyAdvancing? [2022]: Growing, Evolving, And Accelerating At Exponential Rates –Zippia. [online] Zippia.com. Available at: https://www.zippia.com/advice/how-fast-is-technology-advancing/
Staff, V., 2021. Report: AI investments see largest year-over-year growth in 20 years. [online] VentureBeat. Available at: https://venturebeat.com/2021/12/06/report-ai-investments-see-largest-year-over-year-growth-in-20-years/#:~:text=Total%20AI%20investment%20reached%20%2477.5,from%20both%20governments%20and%20investors.
.jpg)


You may get in touch via our
contact form or via the following:
+44 20 3650 2299
hola@qoakay.com



We work alongside our clients worldwide.
